Natural language to runnable traffic simulations
This project converts vague traffic requests into executable SUMO scenarios by separating structured parameter extraction from open-ended geometry reasoning, then keeping human corrections as a reusable retraining signal instead of losing them in chat history.
The project covers fine-tuned traffic-parameter extraction from natural-language requests, base-LLM geometry reasoning and XML fallback, and Seoul traffic-data grounding with statistical fallbacks. It also includes execution orchestration, held-out evaluation, correction logging, retraining export, and live admin review.
Why is this hard?
Creating traffic simulations is still too inconvenient, too slow, and too unrealistic for a natural-language workflow.
Turning a traffic scene into a simulation is still inconvenient and expensive. Building it manually takes too long because road lookup, network construction, config generation, execution, and validation all have to be handled as separate steps before the user can even inspect one result.
Trying to generate the same thing with an LLM is faster, but it often does not represent the real scene well enough. Natural-language requests mix congestion, road type, lane count, speed regime, spacing, and driver behavior, and a general model often fails to convert that into realistic traffic parameters and believable road geometry.
So the result can sound plausible as text while still feeling unrealistic once it is actually run in SUMO. Manual creation takes too long, and LLM-only generation often does not reflect the traffic scene with enough fidelity to be useful.
This project asks: can fine-tuned LLM extraction and a role-separated workflow translate natural-language traffic scenes into runnable simulations with higher fidelity, while making the overall generation process fast enough to use as an actual workflow?
Teach traffic-scene context from real road data, then split generation by responsibility
Build the missing traffic-scene dataset first, fine-tune the language-to-parameter layer, then let specialized components assemble the final simulation.
There is no ready-made dataset that cleanly maps natural-language traffic scenes to simulation-ready parameters, so the project first builds that supervision itself. Real road data from Seoul traffic detectors and synthetic traffic-engineering scenarios are turned into prompt-target pairs, so the fine-tuned model can learn how natural-language descriptions map to structured traffic context instead of only memorizing road names or generic prompt patterns.
Once that layer is learned, generation is split by role. The fine-tuned extractor produces structured traffic parameters, the geometry LLM classifies edits and handles geometry reasoning and XML fallback, and the surrounding system rebuilds the network, runs SUMO, and validates the result. Because traffic-scene data is still scarce, the system also logs correction-intent edits and exports them as retrainable data, so the model can keep improving as more real usage accumulates.
The broader project also includes live Seoul traffic lookup, representative road-type statistics, and similar-road estimation tools that support grounding and fallback around the main generation flow.
Build traffic-scene supervision
Extract prompt-target data from real road observations and synthetic scenarios because off-the-shelf natural-language traffic-scene datasets do not really exist.
Fine-tune language to traffic parameters
Teach the model to read the context of a traffic scene from natural language and output structured fields such as speed, volume, lanes, sigma, tau, and spacing.
Split parameter, geometry, and execution roles
Use specialized components across the fine-tuned extractor, the geometry LLM, and the tool-calling agent so each part handles the part it is best at.
Keep extracting retrainable data
Log correction-intent feedback, separate it from tuning requests, and export reusable training data so the system can be tuned again over time.
Real Seoul traffic data becomes supervised prompt–parameter pairs
Extract observed speed and volume from detector data, estimate driver behavior parameters, then diversify prompts so the model learns traffic situations — not road-name lookup.
Training data comes from Seoul Metropolitan Government detector records (2025.10): speed data covering 31-day hourly averages per road segment,
volume data with hourly counts per collection point, and the national standard node-link SHP for speed limits and road geometry.
The fine-tuned model is gpt-4.1-mini via the OpenAI Fine-Tuning API.
~70 road segments × 7 time periods × 5 prompt variants = ~2,450 total pairs, split 90/10 into train (2,205) and validation (245).
flowchart LR
A["Speed detectors\n31-day hourly avg"] --> D["Match by\nroad name & link ID"]
B["Volume detectors\nhourly count"] --> D
C["Node-link SHP\nspeed limit · geometry"] --> D
D --> E["Group by 7\ntime periods"]
E --> F["Reverse-estimate\nsigma, tau\n(Greenshields)"]
F --> G["Generate 5\nprompt variants"]
G --> H["train JSONL\n2,205 (90%)"]
G --> I["val JSONL\n245 (10%)"]
| Parameter | Source | Method |
|---|---|---|
speed_kmh | Observed | 31-day hourly average from speed detectors |
volume_vph | Observed | Hourly average from volume detectors |
lanes | Observed | Mode of lane counts across link segments |
speed_limit_kmh | Observed | Node-link SHP MAX_SPD; road-type heuristic fallback |
avg_block_m | Observed | Mean link length from node-link geometry |
sigma | Estimated | Greenshields reverse-estimation from observed speed |
tau | Estimated | Greenshields reverse-estimation from observed speed |
reasoning | Generated | Rule-based summary of the above values |
Each (road, time period) pair produces 5 prompt variants so the model learns from traffic situations, not road name lookup.
All prompts are originally in Korean — translated for display.
| Style | Template | Example (translated) |
|---|---|---|
| Road name + time + action | {road} {time} {action} |
"Simulate Yangjae-daero afternoon" |
| Road name + time | {road} {time} |
"Yangjae-daero afternoon" |
| Situational (no name) | {congestion} {area} {road_type} {lanes}-lane {time} |
"moderate suburban arterial 8-lane afternoon" |
| Generic type + time | {lanes}-lane {road_type} {time} traffic simulation |
"8-lane arterial afternoon traffic simulation" |
| Mixed | {road}-like {road_type} {time} conditions |
"Yangjae-daero-like arterial afternoon conditions" |
The strongest gain appears in the structured extraction layer
| Field | Fine-tuned | Base |
|---|---|---|
| speed_kmh | 5.1% | 74.6% |
| volume_vph | 34.8% | 48.1% |
| lanes | 8.9% | 13.9% |
| speed_limit_kmh | 1.7% | 23.8% |
| sigma | 4.5% | 21.3% |
| tau | 4.6% | 11.4% |
| avg_block_m | 14.5% | 167.6% |
| Overall | 10.6% | 51.5% |
Benchmark: 30 held-out prompts with labels derived from real Seoul traffic data. The qualitative shift is not just lower error, but also lower domain bias in speed and block-spacing prediction.
Overall MAPE drops from 51.5% to 10.6%
The fine-tuned extractor reduces structured prediction error by about five times on the held-out benchmark.
Speed bias is dramatically reduced
The base model defaults toward unrealistic free-flow speed, while the fine-tuned model brings the estimate much closer to observed traffic conditions.
Volume still needs more supervision
volume_vph remains the hardest field and the clearest candidate for richer future training data.
Prompt to runnable simulation, then back to reusable evidence
The workflow has two connected halves: an online generation path that turns requests into SUMO runs, and a review path that classifies human edits so the system can improve without contaminating its own data.
flowchart TD
A[User Natural-Language Request] --> B[Fine-Tuned Parameter Extraction]
B --> C[Structured Scenario Parameters]
C --> D{Usable real location?}
D -->|Yes| E[OSM-Based Network Retrieval]
D -->|No / Failed| F[Geometry LLM — XML Generation]
E --> G[SUMO Network Build]
F --> G
C --> H[Demand / Route / Config Generation]
G --> I[Runnable SUMO Artifacts]
H --> I
I --> J[Scenario Execution]
J --> K[Validation and Statistics]
K --> L[User Review]
L --> M{Intent}
M -->|Correction| N[Trainable Signal]
M -->|Tuning| O[Analysis Only]
N --> P[Correction Export]
P --> Q[Future Fine-Tuning Data]
flowchart LR
subgraph Frontend
UI["Web UI\nindex.html"]
AdminUI["Admin Dashboard"]
AboutUI["About Page"]
end
subgraph Backend["server.py"]
SSE["SSE Streaming"]
API["REST API"]
end
subgraph LLM["LLM Layer"]
FT["Fine-tuned Model\ngpt-4.1-mini FT"]
Base["Base LLM\nGPT / Gemini / Claude"]
Agent["Tool-Calling Agent\n11 tools"]
end
subgraph Tools
OSM["OSM Network"]
SUMO["SUMO Generator"]
TOPIS["TOPIS API"]
Valid["Validator"]
end
subgraph Data
DB[("SQLite DB")]
JSONL["Training JSONL"]
end
UI -->|"POST /api/simulate"| SSE
AdminUI -->|"GET /api/admin/*"| API
SSE --> FT --> Base --> SUMO
Agent --> Tools
SUMO --> DB
DB -->|"export"| JSONL
{
"speed_kmh": 18.5,
"volume_vph": 2400,
"lanes": 2,
"speed_limit_kmh": 30,
"sigma": 0.72,
"tau": 0.9,
"avg_block_m": 120,
"reasoning": "School zone, 30km/h limit. Morning drop-off congestion, V/C ~0.85."
}
Constrained prompts turned format errors from 15% to zero
The fine-tuned model uses a structured system prompt that enforces strict JSON output, required fields, and value-range constraints. This is not a minor implementation detail — without these constraints the model intermittently returned prose, markdown, or partial JSON, making the downstream pipeline unreliable.
- Strict JSON-only output — no prose, no markdown, no commentary
- All 8 numeric fields required in every response — never empty or
"-" - Value ranges enforced:
sigma0–1,tau0.5–3,lanes1–8 - Domain reasoning required in the
reasoningfield - Korean road names and locations supported
- School zone —
speed_limit_kmh=30, sigma high (0.6+) - Highway / expressway —
speed_limit_kmh=80–100,avg_block_m500+ - Side street / alley —
speed_limit_kmh=30, lanes=1,avg_block_m50–80 - Rush hour — volume high, speed low
- Late night — volume very low, speed high
You are a traffic engineering expert and SUMO simulation engineer.
When the user describes a road/traffic situation, return only JSON
with the parameters needed for SUMO simulation.
You must fill all 8 fields below with numbers.
Never use empty values or the string '-'.
Output format:
{"speed_kmh": number, "volume_vph": number,
"lanes": one-way lane count,
"speed_limit_kmh": number,
"sigma": between 0~1, "tau": between 0.5~3,
"avg_block_m": intersection spacing (m),
"reasoning": "rationale"}
| Version | Approach | Result |
|---|---|---|
rule-v1 | Rule-based keyword matching, no LLM | Baseline; no domain reasoning |
ft-v1 | Fine-tuned with structured constraints | 0% format errors, 10.6% MAPE |
The critical shift was not the model change — it was adding output constraints to the system prompt. Free-form prompting with the same fine-tuned model still produced ~15% JSON failures.
How each subsystem actually works
Greenshields reverse-estimation for sigma and tau speed → V/C → driver behavior calibration
Driver imperfection (sigma) and desired headway (tau) cannot be directly measured from detector data. They are reverse-estimated from observed speed via the Greenshields model.
The observed speed is divided by free-flow speed to get a speed ratio, which is mapped to a V/C ratio. The V/C ratio determines the congestion band, and sigma and tau are calibrated accordingly.
V/C ≈ max(0.05, 1.0 − speed_ratio × 0.85)
For example: observed 15 km/h on a 50 km/h limit road → speed_ratio = 0.33 → V/C = 0.72 → congested band → sigma 0.6–0.8, tau 0.8–1.2 s.
| V/C range | sigma | tau |
|---|---|---|
| > 0.8 (congested) | 0.6 – 0.8 | 0.8 – 1.2 s |
| 0.5 – 0.8 (moderate) | 0.4 – 0.6 | 1.0 – 1.5 s |
| < 0.5 (free-flow) | 0.2 – 0.4 | 1.5 – 2.5 s |
Tool-calling agent — 11-tool orchestration LLM tool-use · autonomous selection
The agent autonomously selects and executes tools based on user requests, using the LLM tool-use feature.
| Tool | Description |
|---|---|
search_location | Geocode area names to coordinates |
build_road_network | Build SUMO network from OSM |
get_traffic_stats | Query local Seoul traffic statistics |
generate_simulation | Generate SUMO config files |
run_sumo | Execute simulation |
query_topis_speed | Real-time Seoul traffic API |
load_csv_data | Load external traffic data |
recommend_road | Suggest similar roads |
find_similar_roads | Find roads matching criteria |
validate_simulation | Validate simulation output |
calibrate_params | Calibrate parameters from results |
Example: input "simulate a congested commute road"
2. get_traffic_stats("arterial","rush hour") → refs
3. generate_simulation(params) → .net/.rou/.sumocfg
4. run_sumo(config) → avg 22.3 km/h, 1850 veh
5. validate_simulation(results) → grade B, −8.2%
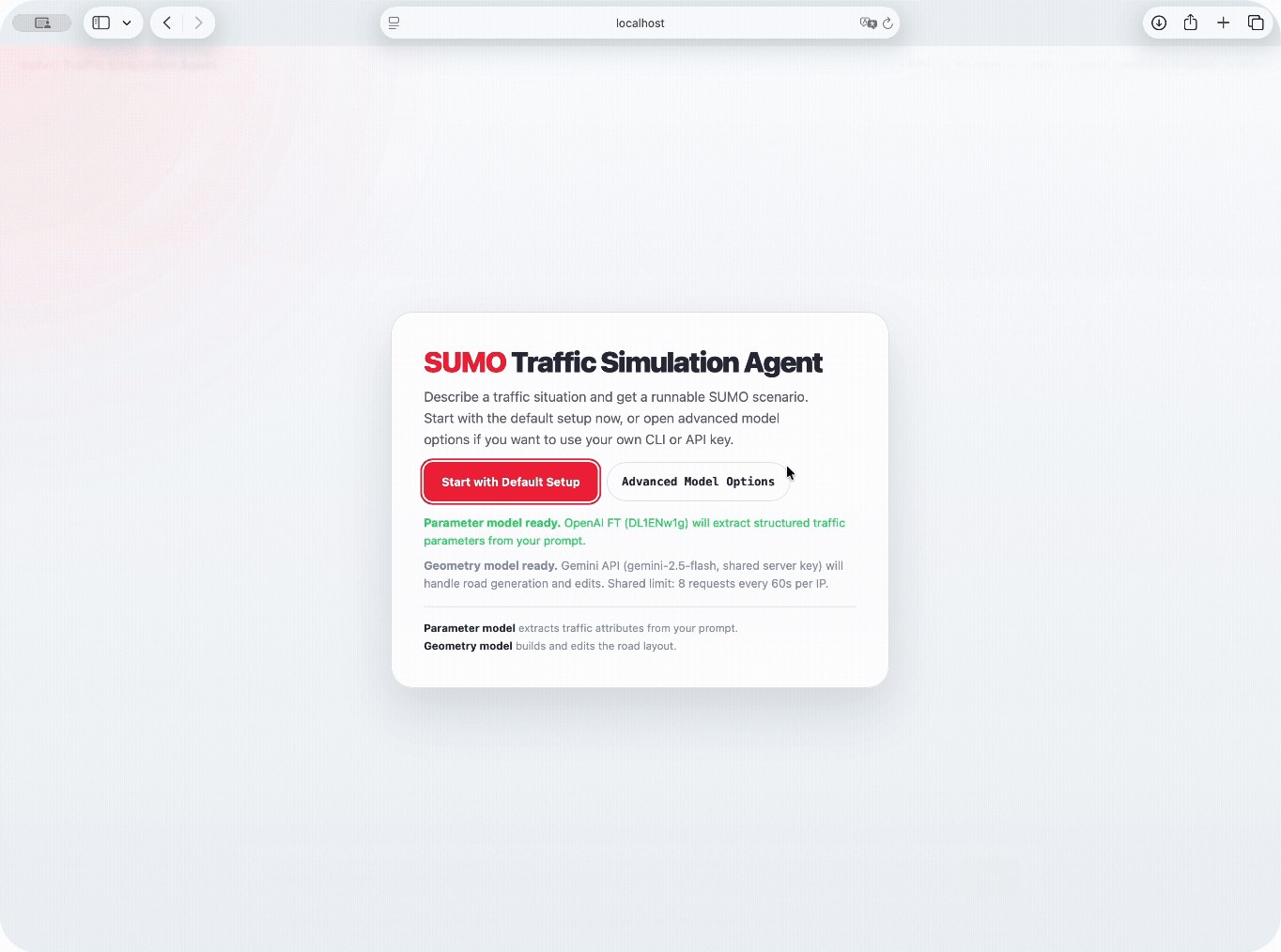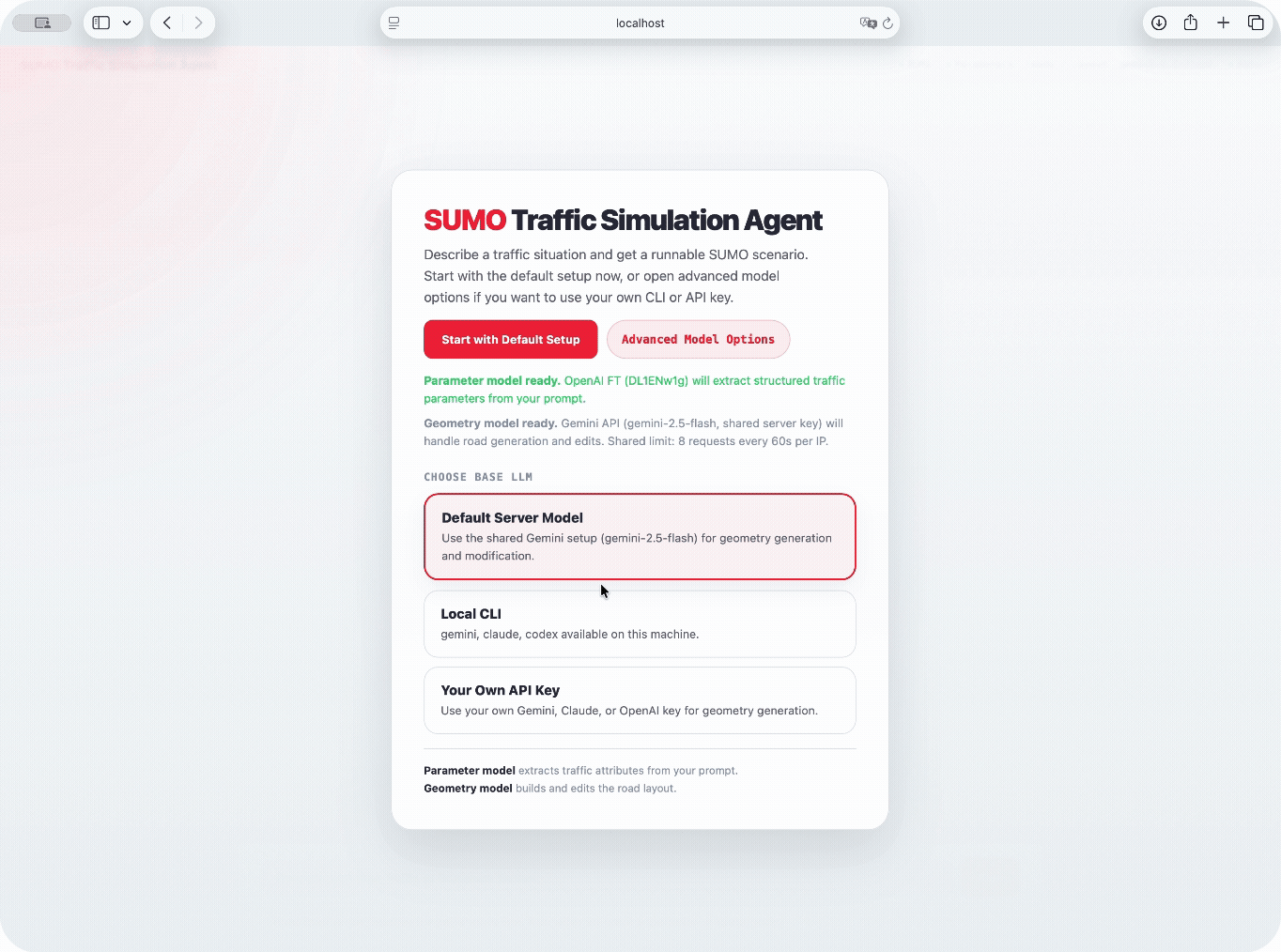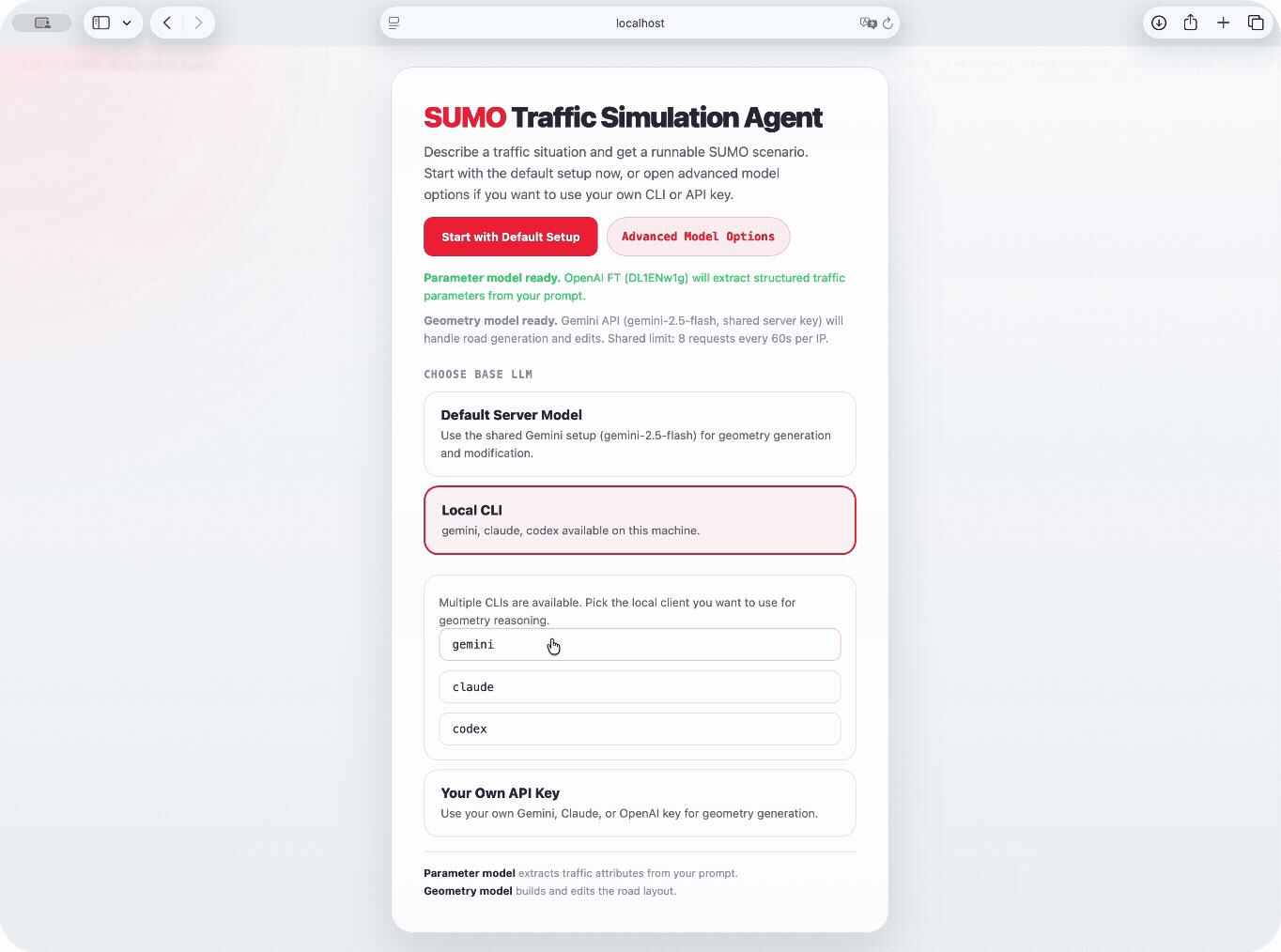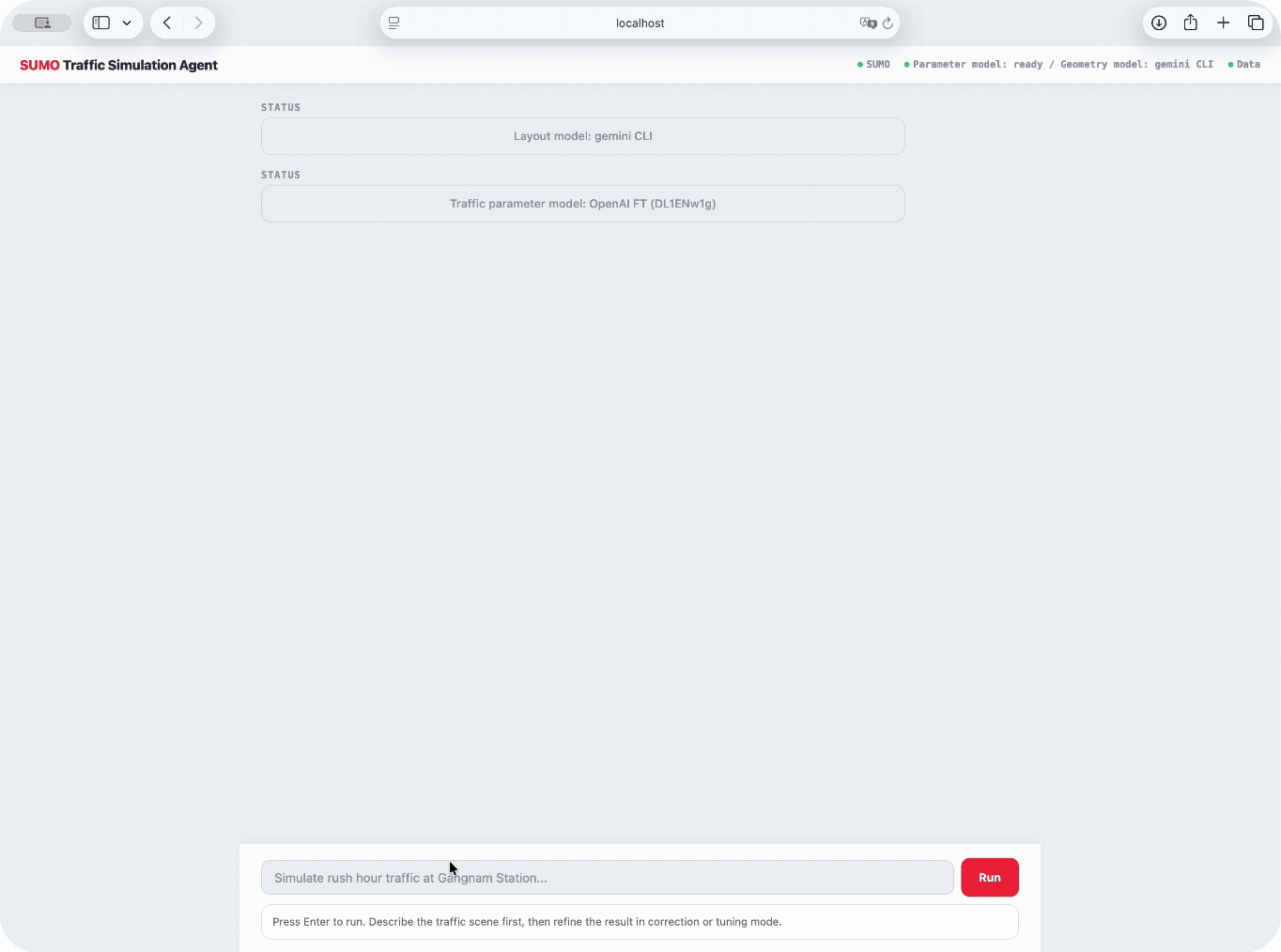
The agent layer uses LLM tool-use. The base LLM is configurable across Claude, GPT, and Gemini.
Role-separated LLM design — 4 components FT extractor · geometry LLM · agent · logging
Each component owns one responsibility. The fine-tuned model does not attempt geometry; the geometry LLM does not attempt structured extraction.
Fine-tuned extractor
Parses natural language into structured simulation parameters. Provides the machine-readable target for the rest of the pipeline.
Geometry LLM
Classifies each user edit as parameter, geometry, or mixed. Handles road layout reasoning and generates fallback XML when OSM fails.
Tool-calling agent
11-tool orchestration via LLM tool-use. Autonomous tool selection based on user intent with multi-turn execution.
Logging and export
Stores simulation runs and modification sessions. Separates trainable corrections from non-trainable tuning. Exports retraining JSONL.
Error pattern analysis — directional bias across 30 samples base overpredicts speed +68%, block spacing +165%
Directional bias reveals where each model systematically over- or under-predicts, beyond just the MAPE number.
| Field | FT Bias | FT Accurate | Base Bias | Base Accurate |
|---|---|---|---|---|
speed_kmh | +0.5% (balanced) | 21/30 | +68.3% (overpredict) | 0/30 |
volume_vph | +25.9% (over) | 13/30 | +21.4% (over) | 3/30 |
speed_limit_kmh | −1.7% (balanced) | 29/30 | +15.7% (over) | 11/30 |
sigma | −0.9% (balanced) | 24/30 | +9.9% (over) | 6/30 |
tau | +1.6% (balanced) | 20/30 | +0.9% (over) | 3/30 |
avg_block_m | −0.6% (balanced) | 20/30 | +165.0% (overpredict) | 1/30 |
Key finding: the base model defaults to free-flow speeds (+68.3% bias, 0/30 accurate) and lacks urban block-structure knowledge (+165% spacing).
Fine-tuning corrects both. The remaining weak point is volume_vph (34.8% MAPE) — the most context-dependent field that would benefit from additional training data.
Modification classification — parameter, geometry, or mixed LLM classifier · keyword fallback
When a user requests a change, the geometry LLM first classifies it before routing to the correct handler.
The geometry LLM receives the user's edit request and returns one word: parameter, geometry, or mixed. If the LLM call fails, a keyword heuristic takes over.
→ "parameter" → update speed/volume/sigma/tau
→ "geometry" → regenerate .nod.xml / .edg.xml
→ "mixed" → both paths, then rebuild
| Type | Examples |
|---|---|
| parameter | "lower the speed", "increase volume to 3000", "make it more congested" |
| geometry | "add an intersection", "bend the road", "make it a 4-way crossing" |
| mixed | "set speed limit to 70 and make road straight", "add lane and raise volume" |
Correction pipeline — human fixes stored in SQLite, exported as retraining data correction vs tuning · trainable flag · JSONL export
Every modification is stored in SQLite with before/after snapshots, modification type, edit intent, and a trainability flag. Only correction-intent records are exported for retraining.
→ Correction: stored with trainable=1
→ Tuning: stored with trainable=0
export_corrections_for_training()
→ SELECT WHERE trainable=1 AND intent='correction'
→ sessions_corrections_openai.jsonl
→ merge with train_real_openai.jsonl → re-fine-tune
This separation prevents preference-driven edits from polluting the fine-tuning signal.
The admin dashboard at /admin shows correction history, modification breakdowns, and downloadable exports.
| SQLite field | Purpose |
|---|---|
edit_intent | "correction" or "tuning" |
trainable | 1 = exportable, 0 = analysis only |
modification_type | parameter / geometry / mixed |
details_json | Before/after parameter snapshots |
| Data source | Samples | Ground truth |
|---|---|---|
| Real-data (Seoul) | ~2,450 | Observed speed/volume |
| Corrections (SQL) | grows over time | Human expert fixes on FT outputs |
Runtime parameter wiring — how FT output becomes a SUMO simulation network XML · vType injection · two kinds of "speed"
The FT model predicts eight fields. Some define the physical road, some describe driver behavior, and speed_kmh serves as the validation target for calibration.
| FT field | Target | SUMO mechanism |
|---|---|---|
speed_limit_kmh | .net.xml | Rewrite lane/edge speed after netconvert |
lanes | .net.xml | Network topology / capacity |
avg_block_m | .net.xml | Intersection spacing (generated geometry) |
sigma | .rou.xml vType | Krauss driver imperfection (0–1) |
tau | .rou.xml vType | Desired headway in seconds |
volume_vph | randomTrips.py | Trip generation rate |
max_speed | .rou.xml vType | Capped at limit × 1.05 |
speed_kmh | Nowhere | Validation target only |
speed_limit_kmh is a legal/physical cap — "cars cannot go faster than this." Written into network XML.
speed_kmh is the predicted average speed under congestion — used for validation and calibration, not written into SUMO files.
A ≤ 10% · B ≤ 20% · C ≤ 30% · D ≤ 50% · F > 50%
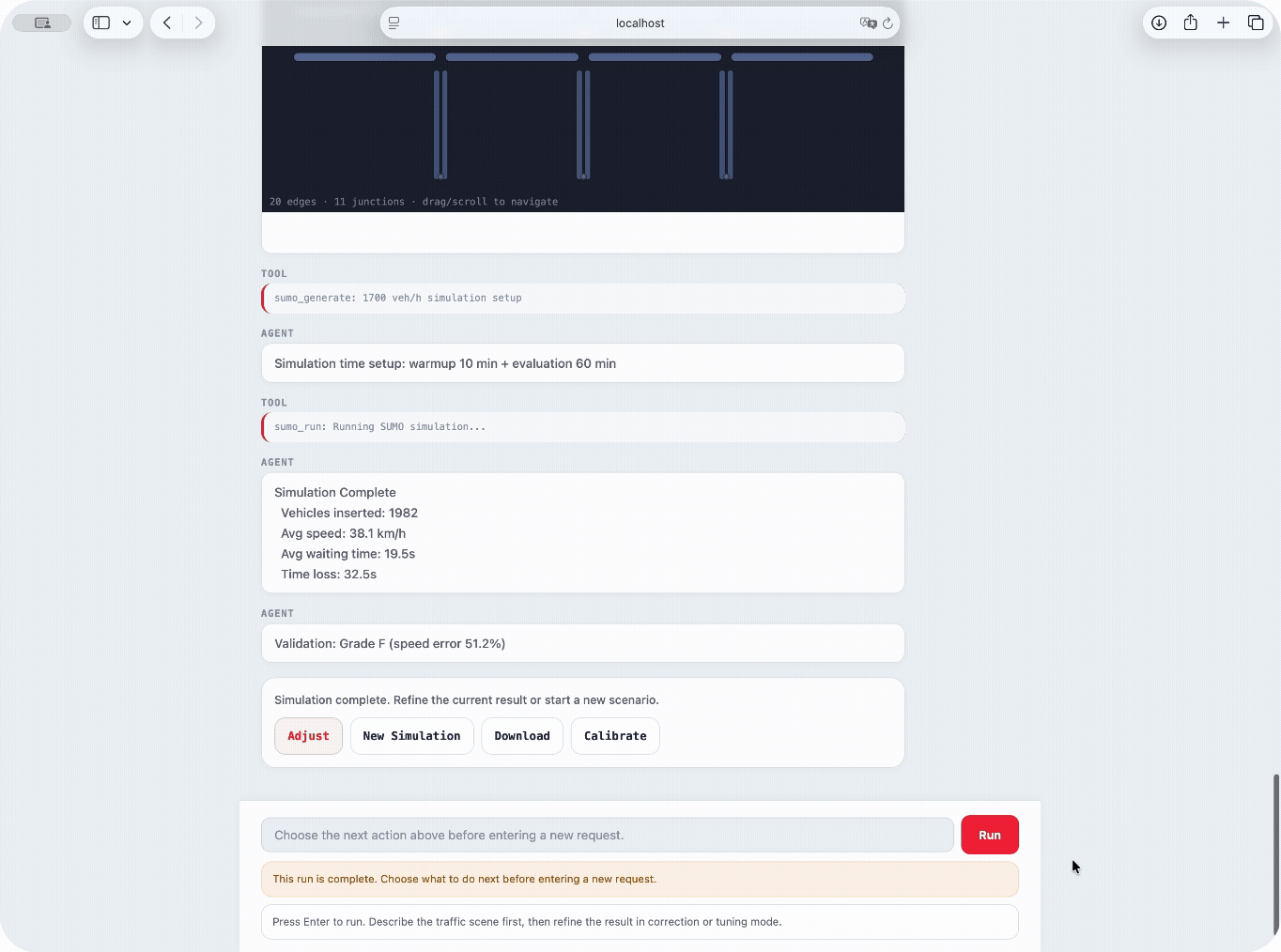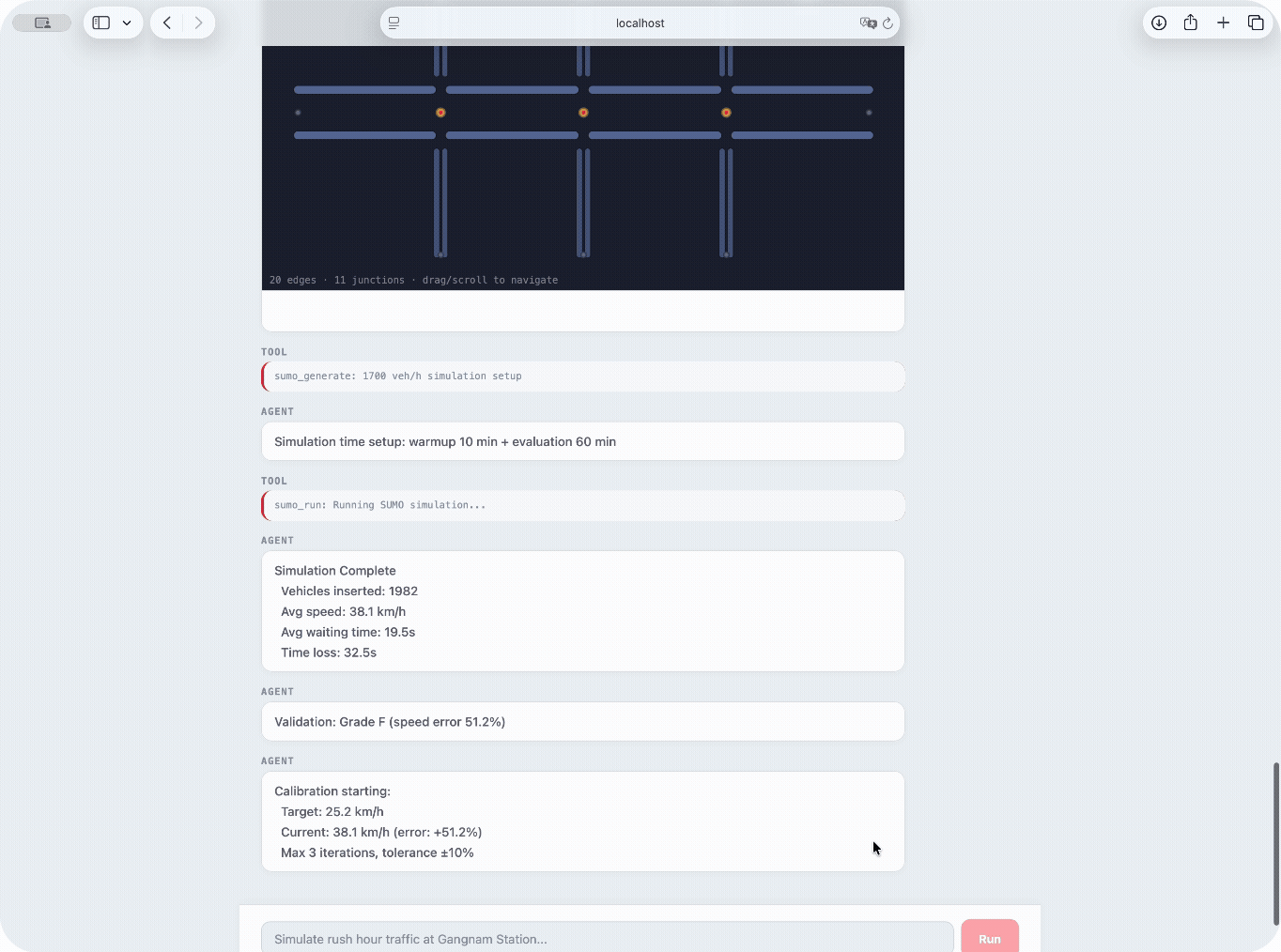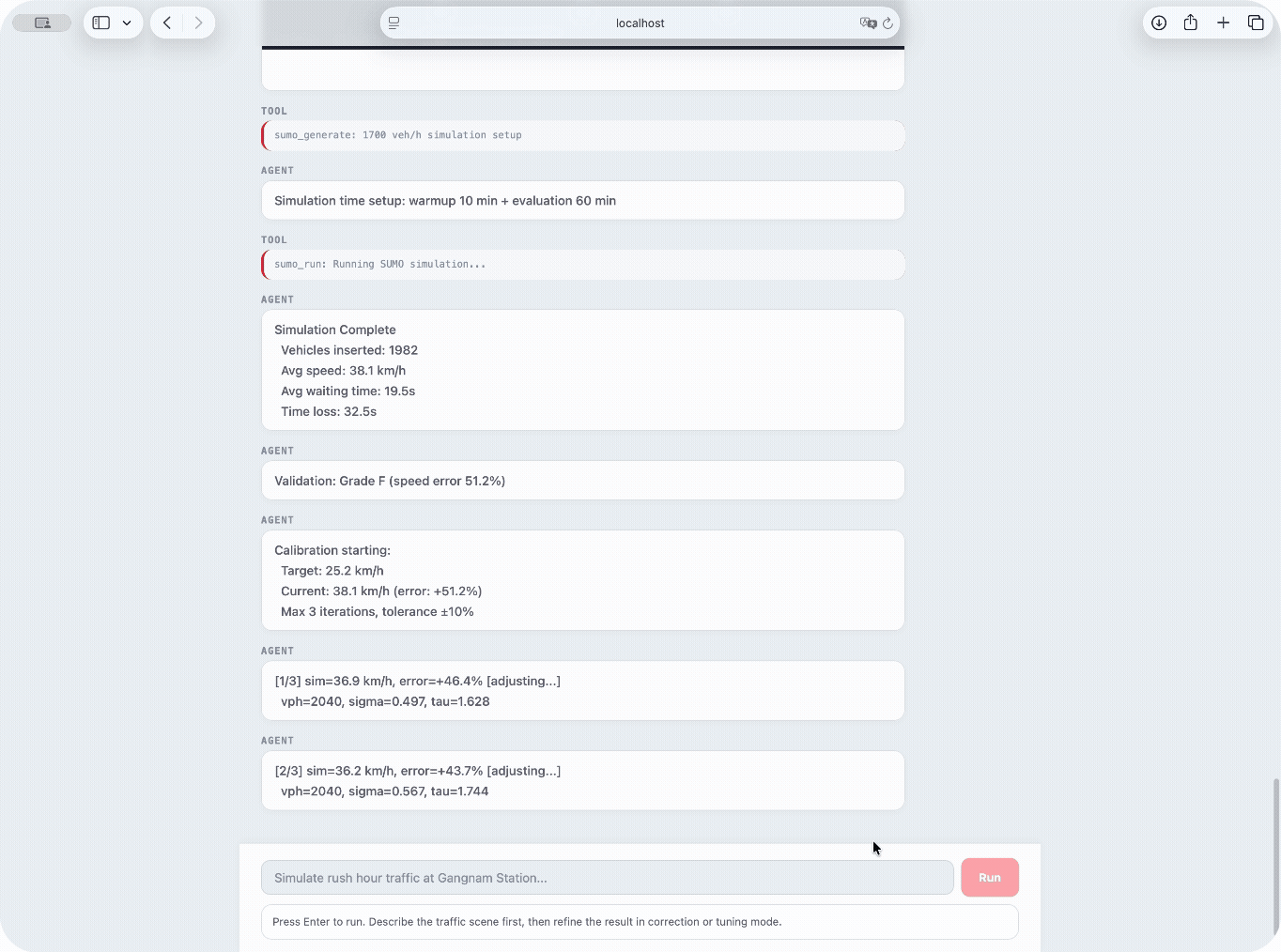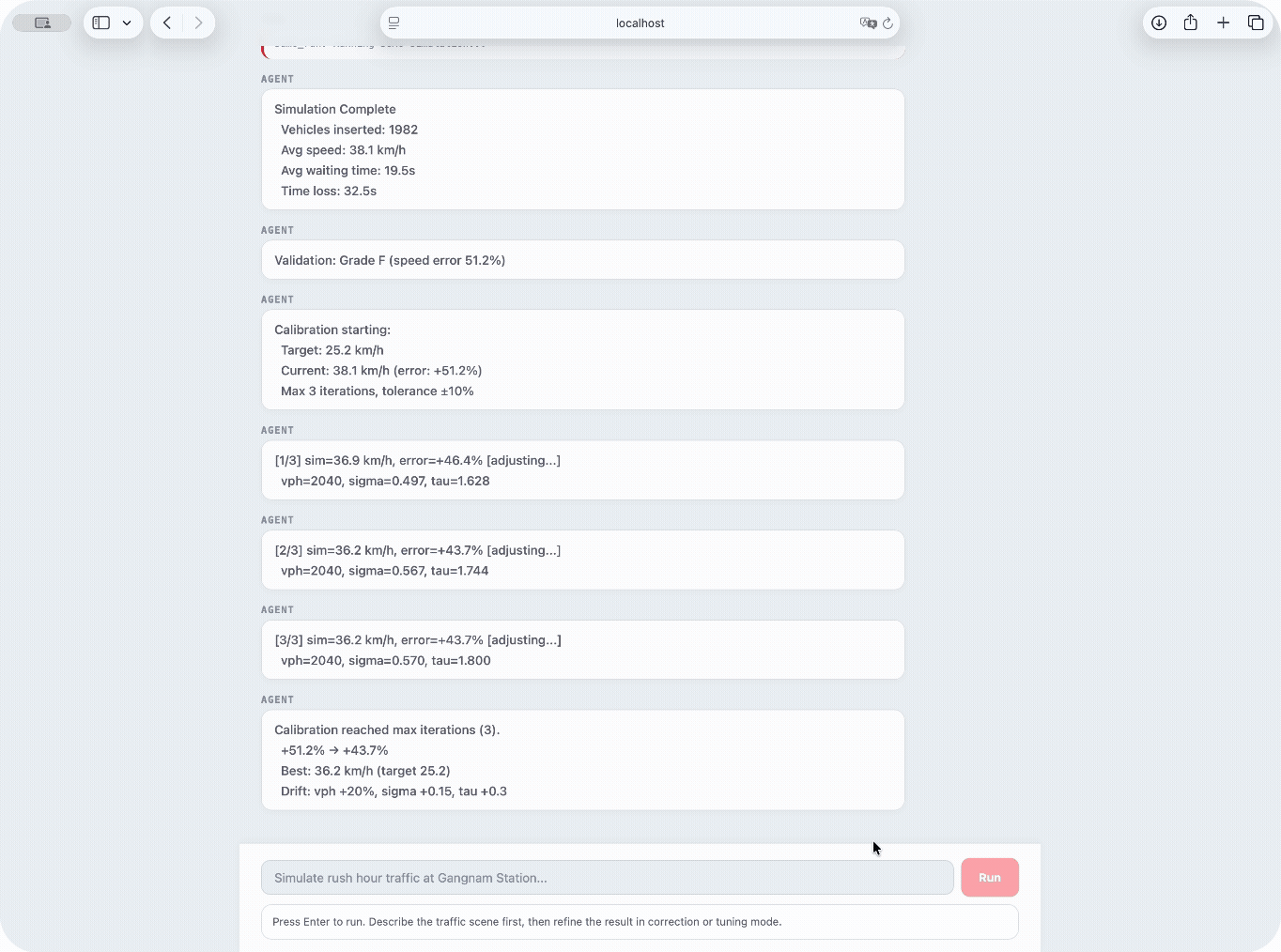
Automatic calibration loop — proportional control with bounded drift volume · sigma · tau · max 3 iterations · ±20% drift cap
When validation error exceeds ±10%, the calibration loop nudges behavioral parameters so the simulated speed converges toward the FT-predicted target.
2. If |error| ≤ 10% → converged, stop
3. Adjust proportionally:
volume × (1 + 0.4 × error)
sigma + 0.15 × error
tau + 0.25 × error
4. Clamp to drift bounds
5. Re-run SUMO → repeat (max 3)
Gains are derived from SUMO Krauss model sensitivity analysis. If all parameters hit drift caps without converging, the loop stops early — the error signals a geometry mismatch rather than a parameter error.
| Parameter | Drift limit | Effect |
|---|---|---|
volume_vph | ±20% | Primary congestion lever |
sigma | ±0.15 | Driver imperfection → capacity |
tau | ±0.3 s | Headway → throughput |
speed_limit_kmh, lanes, avg_block_m, and network geometry are never modified. They define the physical road. Calibration only adjusts how vehicles behave on it.
Calibrated values are stored in calibrated_params_json — separate from the original FT output. This prevents calibration artifacts from contaminating retraining data.
Generate, correct, and tune — all in one conversation
One chat session covers the full cycle. First, pick which LLM handles geometry reasoning. Then describe a traffic scene — the fine-tuned model extracts structured parameters, the system builds the road network, and SUMO executes the scenario. If the result is wrong, open Correction mode: fix the parameter or geometry error, and the delta becomes retraining data for the next fine-tuning round. If the result is acceptable but you want a variant, use Tuning mode instead — the change is logged for analysis but kept out of the training signal so preference edits never pollute the dataset. An optional Calibrate button auto-adjusts behavioral parameters so the simulated speed converges toward the FT-predicted target.
The browser flow is also a real working interface, not just a demo shell: simulation progress streams live,
the generated network is previewed in-chat, the latest SUMO artifact set can be downloaded as a ZIP,
and, in local environments, completed scenarios can be reopened in sumo-gui for manual inspection.
Monitor corrections, inspect error patterns, and export retraining data
The admin dashboard at /admin closes the feedback loop by surfacing what the model got wrong and making correction data directly exportable.
Every correction is traceable end to end: user edit, SQLite log, admin panel, exported JSONL, re-fine-tune.
Without an inspection layer, corrections disappear into chat history. The admin dashboard makes error patterns visible — which fields drift, which geometry types fail, and how often corrections are trainable — so the next fine-tuning round targets the right gaps.
Three downloadable exports close the loop: Corrections JSONL for re-fine-tuning, Evaluation Report for grade distribution and fidelity, and LLM Evaluation Report for field-level error analysis and parameter deltas.
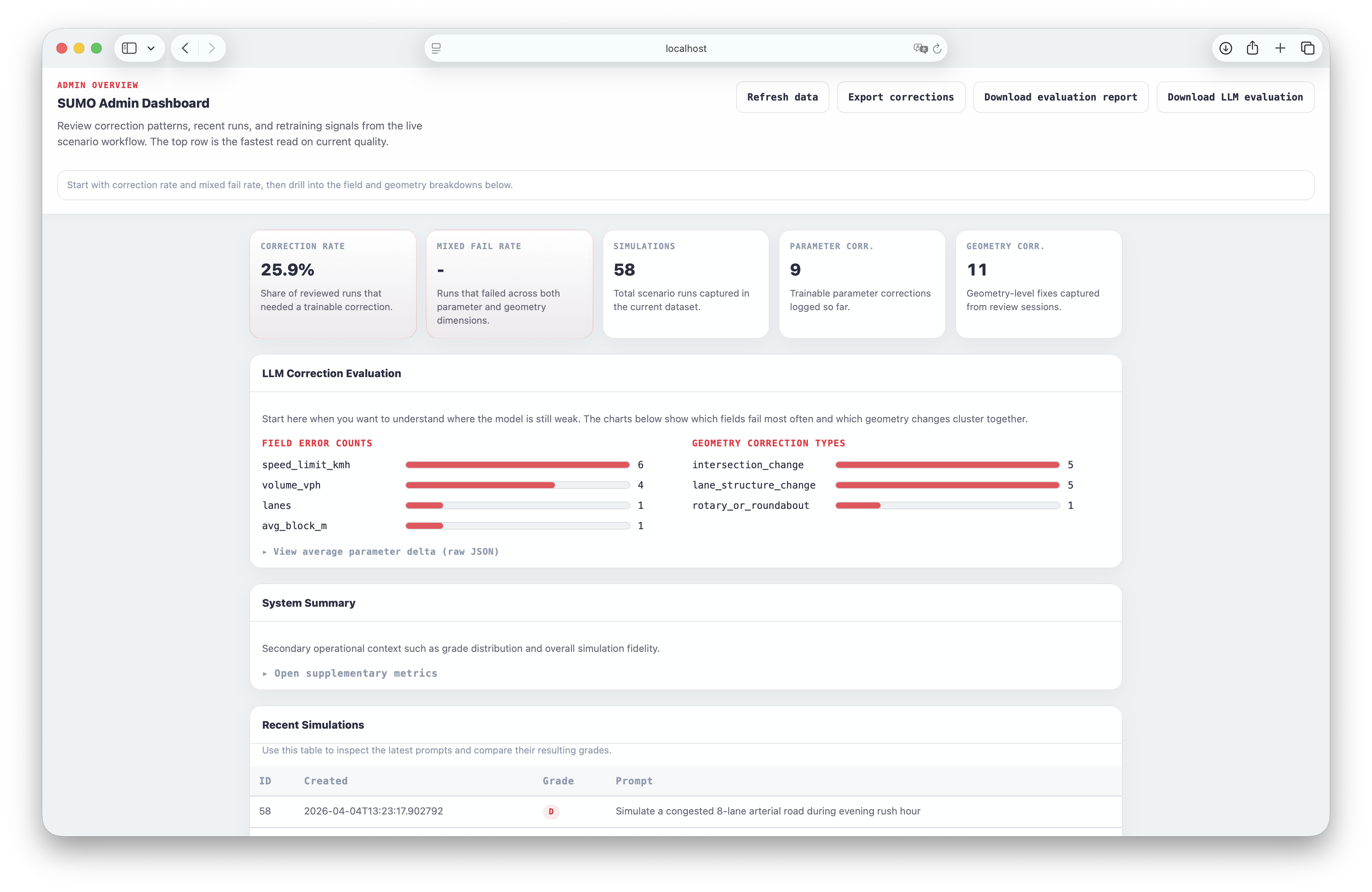
Top-level cards show correction rate and fail rate. The LLM evaluation panel breaks down per-field errors and geometry correction types.
Open admin dashboardTop cards
Correction rate, mixed fail rate, total simulations, parameter/geometry correction counts at a glance.
LLM Correction Evaluation
Per-field error bar charts, geometry correction type breakdown, and average parameter deltas.
Recent Simulations
Prompt, grade (A/B/C/D), and timestamp for the latest 30 runs.
Recent Modifications
Edit intent, modification type, trainable flag, and user input for the latest 50 edits.
What worked, what stayed fragile, and what the project actually proves
The main win is not perfect scenario generation. It is that the system makes evaluation and future improvement structurally possible after deployment.
Fine-tuning works best on constrained, structured outputs. Geometry and XML generation is handled by a general-purpose LLM because fine-tuning it was not feasible within the project's budget — this is the clearest remaining limitation. The second contribution is the review loop: the system preserves correction intent, session history, and export eligibility so human review can become clean retraining signal rather than one-off conversation debris.
Road layout and XML generation still rely on in-context prompting with the geometry LLM. Fine-tuning this layer would require structured geometry datasets and significantly more API budget — a clear next step if resources allow.
Parameter prediction with constrained JSON converged quickly on ~2,450 samples, while open-ended geometry remained too brittle to treat as the main supervised surface.
Without that split, preference-driven edits would silently pollute the exported retraining dataset and weaken future fine-tuning quality.
OSM lookups and external dependencies fail often enough that XML and geometry fallback must remain visible, supported workflow paths rather than hidden error handlers.